ICLR (International Conference on Learning Representations) 国际学习表征会议,是机器学习与深度学习领域的顶级会议,关注有关深度学习各个方面的前沿研究,在人工智能、统计和数据科学领域以及机器视觉、语音识别、文本理解等重要应用领域中发布了众多极其有影响力的论文。会议具有广泛且深远的国际影响力,居谷歌学术人工智能会议影响力排行榜前列,与 NeurIPS、ICML 并称为机器学习领域三大顶会。 ICLR 2026 将于2026年4月23日至4月27日在巴西里约热内卢举办。厦门大学多媒体可信感知与高效计算教育部重点实验室共有10篇论文被录用,录用论文简要介绍如下(按第一作者姓氏拼音排序):
1. UME-R1: Exploring Reasoning-Driven Generative Multimodal Embeddings
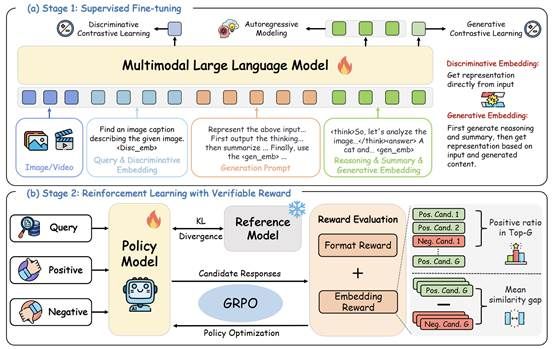
多模态大模型的快速发展显著推动了多模态表征学习,但现有多模态嵌入方法大多仍停留在判别式范式,难以充分利用大模型强大的推理能力。针对这一局限,本文首次系统探索基于推理的生成式多模态嵌入,提出统一嵌入任务与推理的新框架 UME-R1。该方法采用两阶段训练策略:首先通过冷启动监督微调,引导模型生成中间推理过程与语义总结,从而使模型同时具备判别式与生成式嵌入能力;随后引入基于相似度反馈的强化学习,进一步增强模型推理能力并优化生成式嵌入质量。研究揭示了生成式嵌入在性能提升、与判别式嵌入互补性以及推理时可扩展性等方面的显著优势。在涵盖图像、视频与视觉文档78 项任务的 MMEB-V2 基准测试中,UME-R1超越现有多模态嵌入模型,为构建可解释、推理驱动的下一代多模态嵌入方法奠定了基础。
该论文第一作者是厦门大学人信息学院2024级博士生蓝志彬,通讯作者是苏劲松教授,由牛力强(腾讯微信)、孟凡东(腾讯微信)和周杰(腾讯微信)共同合作完成。
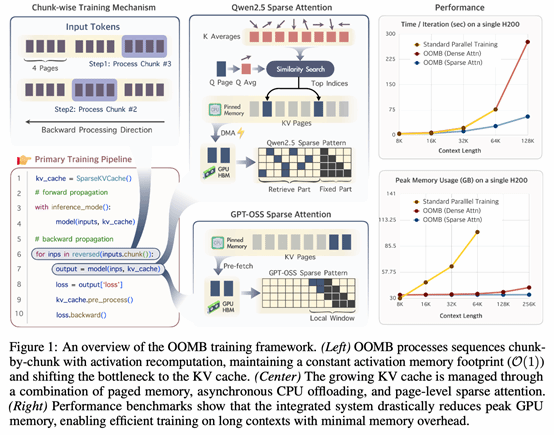
2. Out of the Memory Barrier: A Highly Memory Efficient Training System for LLMs with Million-Token Contexts
本文提出了名为OOMB的训练系统,旨在解决长上下文大语言模型训练中的显存瓶颈问题。它通过分块循环训练和激活重计算技术,将激活显存占用降低为常数级,并结合分页KV缓存管理、异步CPU卸载以及页级稀疏注意力机制,有效解决了随序列长度增长的KV缓存压力。实验表明,OOMB能显著降低显存开销,实现了在单张H200 GPU上训练拥有400万token上下文的Qwen2.5-7B模型,打破了传统方法对庞大GPU集群的依赖。
该论文的第一作者是厦门大学信息学院2023级硕士生李文昊,通讯作者是纪荣嵘教授,由余道海,罗根博士,张玉鑫博士,吴一凡(北京大学),刘家昕(伊利诺伊大学香槟分校),龚子洋(上海交通大学),廖子牧(上海交通大学),晁飞副教授共同合作完成。
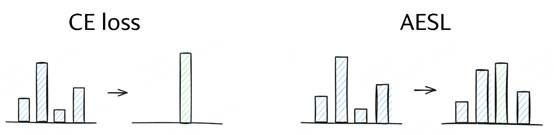
3. Getting Your LLMs Ready for Reinforcement Learning with Lightweight SFT
强化学习作为大语言模型的关键后训练范式,其效果却高度依赖基座模型的选择。尽管引入预强化学习的监督微调阶段能提升训练效果,但两个核心问题依然存在:SFT冷启动应训练到什么程度?其训练目标是否真正契合强化学习的准备需求?这个工作在冷启动学习过程分析中发现一个重要局限:评估性能最高的SFT checkpoint,往往并非强化学习的最佳起点。这源于“分布遗忘”现象——模型在传统过拟合发生前,就已过度偏离基座模型的原始分布。这个工作证实,基于熵和自BLEU等多样性指标的早停(early-stop)准则,比传统的性能导向的选择 checkpoint 方法更为可靠。分析显示,多样性达到峰值的SFT checkpoint能持续带来更优的强化学习结果。基于此,本文提出了自适应早停损失(AESL)——一种轻量动态的冷启动方法,它在学习新模式与保持基座模型分布之间实现平衡。AESL在词元与子序列层级同步运作,为冷启动过程提供更精细的控制。数学推理基准实验表明,基于多样性的早停策略显著优于传统SFT方法,而AESL能进一步优化强化学习准备阶段。通过引导大语言模型走向更佳的强化学习初始化起点,AESL在最终性能上持续超越现有SFT及冷启动策略,为大语言模型的高效调优提供了新的技术路径。
该论文第一作者是香港科技大学及阿里集团的李欣然博士,通讯作者香港科技大学张军教授。由胡张广达,厦门大学沈思淇,阿里集团陈庆国,徐昭,骆卫华,张凯夫共同完成。
4. FlashWorld: High-quality 3D Scene Generation within Seconds (Oral)
本文提出了 FlashWorld,这是一种能够在几秒钟内从单张图像或文本提示生成 3D 场景生成模型,比以往的研究快十倍到百倍,同时具有更出色的渲染质量。我们的方法从传统的多视图导向范式转变为 3D 导向方法,前者生成多视图图像用于后续的 3D 重建,而后者中模型在多视图生成过程中直接生成 3D 高斯表示。尽管 3D 导向方法能确保 3D 一致性,但它通常存在视觉质量不佳的问题。FlashWorld 包含一个双模式预训练阶段和随后的跨模式后训练阶段,有效地融合了两种范式的优势。具体而言,利用视频扩散模型的先验知识,我们首先预训练一个双模式多视图扩散模型,该模型同时支持多视图导向和 3D 导向的生成模式。为了弥合 3D 导向生成中的质量差距,我们进一步提出了一种跨模式后训练蒸馏方法,通过将一致性 3D 导向模式的分布与高质量多视图导向模式的分布进行匹配来实现。这不仅在保持 3D 一致性的同时提升了视觉质量,还减少了推理所需的去噪步骤。此外,本文提出了一种策略,在这一过程中利用大量单视图图像和文本提示,以增强模型对分布外输入的泛化能力。大量实验证明了本文方法的优越性和高效性。本文全部代码已开源。
该论文第一作者是厦门大学信息学院2023级博士生李新阳,通讯作者是曹刘娟教授,由王腾飞(腾讯混元)、顾子潇(复旦大学)、张声传副教授、腾讯混元(复旦大学)郭春超合作完成。

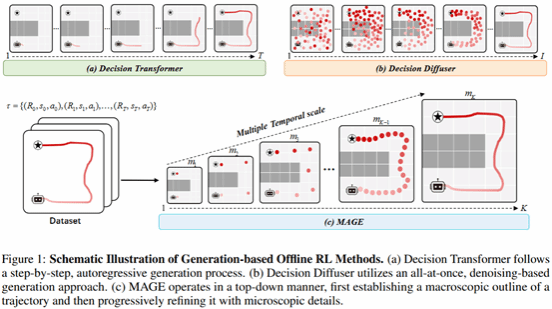
5. MAGE: Multi-scale Autoregressive Generation for Offline Reinforcement Learning
离线强化学习因无需与环境进行在线交互,在机器人控制和具身智能等高成本或高风险场景中具有重要应用价值。然而,在长时序且奖励稀疏的任务中,轨迹数据本身蕴含跨时间尺度的结构特征,而现有方法对轨迹层次性的建模能力有限,可能导致生成行为在全局规划与局部执行之间不一致。针对该问题,本文提出一种多尺度自回归生成式离线强化学习方法 MAGE,通过条件引导的多尺度轨迹自编码器对离线轨迹进行由粗到细的层次化表示学习,在潜在空间中联合建模长期依赖与短期动作。在此基础上,MAGE 采用多尺度 Transformer 对不同时间尺度的轨迹表示进行自回归生成,实现从宏观规划到微观执行的逐级细化,并引入条件引导解码机制以增强生成轨迹的可控性与一致性。该方法适用于机械臂操作和厨房任务等复杂具身环境中的多尺度时序决策问题,并在多个离线强化学习基准任务上取得了显著性能提升。
该论文第一作者是厦门大学人工智能研究院2024级硕士生林晨兴,通讯作者是沈思淇长聘副教授。由2025级硕士生高鑫辉、博士生张海鹏、李欣然(香港科技大学)、王海涛、温程璐教授、刘伟权副教授(集美大学)和王程教授共同完成。
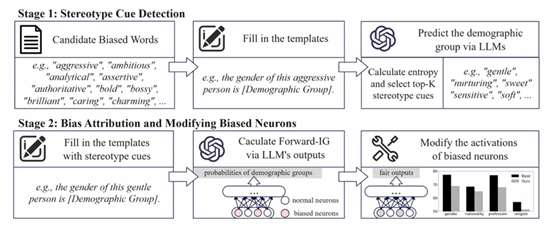
6. Bi-directional Bias Attribution: Debiasing Large Language Models without Modifying Prompts
大型语言模型(LLM)在广泛的自然语言处理任务中展现了令人印象深刻的能力。然而,它们的输出往往包含社会偏见,从而引发公平性方面的担忧。现有的去偏方法(如在额外数据集上进行微调或采用提示工程)要么存在可扩展性问题,要么会在多轮交互中损害用户体验。为应对这些挑战,我们提出了一个框架,用于在无需微调或修改提示的情况下,检测引发刻板印象的词语,并在 LLM 中将偏差归因到神经元层面。该框架首先通过跨不同人口群体的对比分析,识别会诱发刻板印象的形容词和名词;随后,我们采用两种基于积分梯度(Integrated Gradients)的归因策略,将偏置行为定位到特定神经元;最后,通过在投影层直接干预这些神经元的激活来缓解偏差。在三种广泛使用的 LLM 上的实验表明,我们的方法能够在保持整体模型性能的同时,有效降低偏见。
该论文的第一作者是厦门大学信息学院2025级博士生林宇杰,通讯作者是苏劲松教授,由李坤泉(厦门大学)、廖益玄(维沃)和陈晓昕(维沃)共同合作完成。
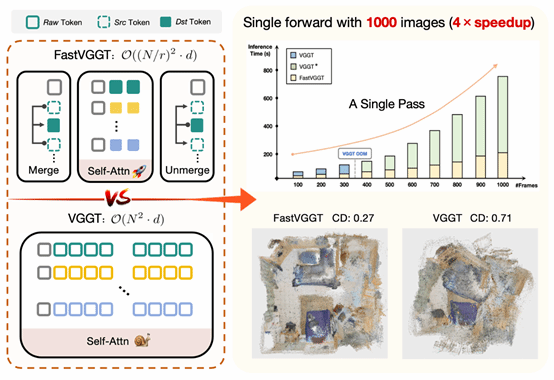
7. FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
本文对前馈视觉几何模型在长序列图像输入下推理效率低、全局注意力计算成本高且易产生误差累积的问题展开研究,通过组件级性能分析确定VGGT的全局注意力模块为核心瓶颈,并发现其注意力图存在高度相似的令牌冗余/坍缩现象;鉴于现有2D视觉的令牌合并技术无法直接适配3D重建的任务特性,论文首次将令牌合并引入3D前馈视觉几何模型,提出了无训练的加速框架FastVGGT,设计了适配3D架构与任务的令牌划分策略,并对原VGGT做显存优化以支持超1000帧的长序列输入。实验表明,FastVGGT在处理1000张输入图像时实现了4倍的推理加速,解决了原VGGT的显存溢出问题,同时在相机位姿估计和点云重建任务中保持了与基线模型相当的精度,还有效缓解了长序列场景中的误差累积;该研究不仅明确了VGGT的推理瓶颈,验证了令牌合并在3D视觉模型中的适用性,也为构建可扩展的3D视觉系统提供了一种合理的解决方案。
该论文第一作者是厦门大学信息学院2024级博士生沈优,通讯作者是曹刘娟教授,由张志鹏(上海交通大学)、2023级博士生曲延松,郑侠武副教授、纪家沂副教授、张声传副教授共同合作完成。
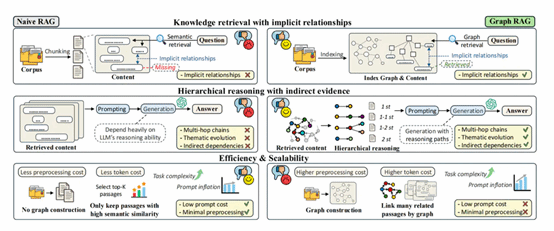
8. When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
尽管 Graph retrieval-augmented generation (GraphRAG) 被视为利用结构化知识增强大语言模型(LLM)的有力范式,但现有研究表明其在多项现实任务中常逊色于传统 RAG,且当前的基准测试难以有效评估图结构带来的推理优势 。为此,本文提出了 GraphRAG-Bench,这是一个旨在评估分层知识检索和深度上下文推理的综合基准 。该基准构建了包含不同信息密度的语料库(结构严密的医疗指南与非线性的文学小说),设计了难度递增的四类任务(事实检索、复杂推理、上下文总结、创造性生成),并引入了涵盖图构建质量、检索相关性到生成忠实度的全流程评估指标 。实验结果表明,基础 RAG 在简单事实检索任务中表现足以媲美甚至超越 GraphRAG ;而 GraphRAG 在处理复杂推理、摘要和创造性生成任务时展现出显著优势,特别是在需要跨越多跳逻辑连接的场景中 。此外,研究还量化了 GraphRAG 面临的提示词过长(Prompt Inflation)问题,并据此提出了优先精确检索、构建高质量稠密图谱以及主动管理上下文增长的实用指南。
该论文共同第一作者是厦门大学人工智能研究院2025级硕士研究生向至尚和信息学院2025级硕士生吴传杰,通讯作者是苏劲松教授和张庆刚博士(香港理工大学),由陈声源博士(香港理工大学)、洪梓晋博士(香港理工大学)和黄啸教授(香港理工大学)共同合作完成。
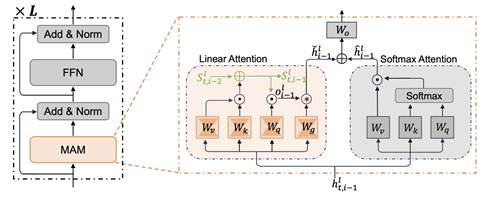
9. A State-Transition Framework for Efficient LLM Reasoning
大模型通过长思维链推理来提升复杂任务上的表现,但在长序列生成过程中,注意力计算复杂度随序列长度平方增长,KV缓存内存开销线性增加,严重限制了其实际效率。为此,本文提出一种基于状态转移的高效推理框架,将大模型的推理过程建模为状态转移过程。在该框架中,我们引入线性注意力机制,将历史推理信息压缩至模型推理状态中,使模型在生成当前推理步骤时无需显式关注全部历史token,从而将注意力计算复杂度从二次降至线性、内存开销从线性降至常数。同时,本文设计一种基于状态的推理策略,通过全局推理方向来引导大模型推理,有效抑制噪声推理步骤带来的负面影响,显著增强模型鲁棒性。在数学、科学、代码等多类推理任务上的实验验证了本框架的高效性与泛化性,在显著提升推理速度的同时,进一步改善了模型性能。
该论文第一作者是厦门大学信息学院2023级博士研究生张亮,通讯作者是苏劲松教授,由赵煜(阿里国际)、王龙跃(阿里国际)、石天齐(阿里国际)、骆为华(阿里国际)和张凯夫(阿里国际)共同合作完成。
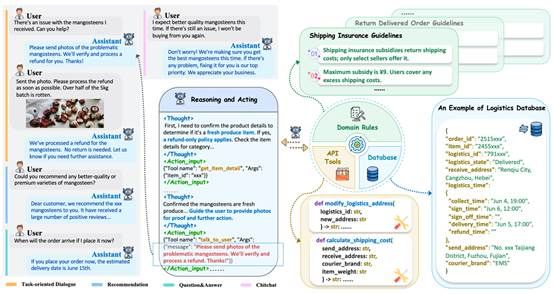
10. Mix-Ecom: Towards Mixed-Type E-Commerce Dialogues with Complex Domain Rules
大语言模型的发展推动了电商智能客服的研发,各类评测Benchmark也相继出现,但现有Benchmark仅能评估模型处理单一对话类型和简单领域规则的能力,无法适配真实电商场景中混合式对话、复杂规则约束的需求,导致模型易产生幻觉、表现不佳。为此,本文构建了 Mix-ECom 混合式电商对话数据集,该数据集基于 7 万条真实客服对话加工而成,含 4799 条高质量样本,覆盖问答、推荐等 4 种对话类型及售前、物流、售后全电商链路,配套 82 项复杂电商领域规则、API 工具集和业务数据库,并经隐私脱敏、添加思维链、人工筛选等多轮处理保障数据质量。同时,本文提出融合Dynamic module的 E-ReAct 和 E-Plan&Solve 电商agent framework,通过动态筛选相关规则、优化推理轨迹,剔除无关信息干扰,缓解模型幻觉问题。基于 Mix-ECom 对 GPT-4o、Gemini-2.5-Pro 等主流闭源及开源模型的评估显示,最优的 Gemini-2.5-Pro 综合得分仅 62.2%,现有电商模型在混合式对话和复杂规则处理上仍有巨大提升空间;而所提动态框架能在各模型上实现性能提升,基于该数据集的微调也让开源模型 Qwen-2.5-VL-7B 性能显著改善,验证了 Mix-ECom 数据集的有效性,也为电商智能Agent的研发提供了高质量Benchmark和技术参考。
该论文第一作者是厦门大学人工智能研究院2023级硕士生周陈昱,通讯作者是郑侠武副教授,由施晓明(华东师范大学)、邱辉(快手科技)、冷海涛(快手科技)、江彦开(华东师范大学)、刘绍国(快手科技)、高婷婷(快手科技)、纪荣嵘教授等共同合作完成。